The non-central chi-squared distribution 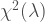
i. a mixture representation (2.2) where 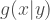
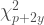
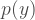

ii. the sum of a 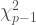

(a) Show that both representations hold
By definition of the noncentral chi-squared distribution 

where 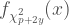


On the other hand, for any 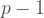



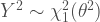

(b) Show that the representations are equivalent if

Note that if 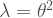

(c) Compare the corresponding algorithms that can be derived from these representations. among themselves and also with chisq for small and large values of

The figure below compared the algorithms defined by (i) and (ii), and the rchisq function in R. 

#ex 2.21
#rep (i): mixture
algorithm1<-function(n, df, ncp){
y<-rpois(n, ncp/2)
rchisq(n, df+2*y, 0)
}
#rep (ii): sum of two chi-squared r.v.
algorithm2<-function(n, df, ncp){
x2<-rchisq(n, df-1, ncp=0)
y<-rnorm(n, sqrt(ncp), 1)
x2+y^2
}
par(mfrow=c(2,3))
set.seed(100)
n<-1e5
df<-2
#Q-Q plots of three non-central chi-squared generators
#two ncp are used, one larger and the other one smaller
for(ncp in c(0.1, 100)){
rv.rchisq<-rchisq(n, df, ncp)
rv.alg1<-algorithm1(n, df, ncp)
rv.alg2<-algorithm2(n, df, ncp)
qqplot(rv.alg1, rv.alg2, pch=”.”, main=paste0(“Q-Q Plot: algorithm (i) vs algorithm (ii)\nncp = “, ncp),
xlab=”Algorithm (i)”, ylab=”Algorithm (ii)”)
abline(0,1,col=”red”)
qqplot(rv.alg1, rv.rchisq, pch=”.”, main=paste0(“Q-Q Plot: algorithm (i) vs rchisq\nncp = “, ncp),
xlab=”Algorithm (i)”, ylab=”rchisq”)
abline(0,1,col=”red”)
qqplot(rv.alg2, rv.rchisq, pch=”.”, main=paste0(“Q-Q Plot: algorithm (ii) vs rchisq\nncp = “, ncp),
xlab=”Algorithm (ii)”, ylab=”rchisq”)
abline(0,1,col=”red”)
}
