There’s no way around it: I’m a fan of procrastinating. But I try to procrastinate in ways that teach me something or that help me learn… which is why one of the things I like to do when procrastinating is figuring out algebraic relationships of things. Which brings us to this nice little result that taught me something a tad bit deeper than I expected. Let me begin.
A few months ago an interesting question was posed on Twitter inquiring about the relationship between the 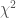

Now, because I’m a huge stats nerd, I know that the 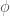
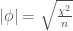
So the first thing I do is go to the Wikipedia entry for the

That’s it. No proof, no explanation. Just a throwaway statement that these things are equal without elaboration. Perhaps Lord & Novick’s (1968) Statistical Theories of Mental Test Scores can offer some guidance? I mean, that book has everything psychometrics in it. I go. I check. And I find this on p.336:

Again, no luck. But a clue has been offered: “It can be shown after tedious algebra (…)”. If you’ve read old math/stats books/articles/etc. (they don’t mince words when describing things), then you know the chances of finding out a formal proof of this are slim to none. This is one of those things that amounts to what I call a “bookkeeping proof”. The kind of proof that relies mostly on being careful with how things are defined, which subscripts should be used where, etc., but the technique is really just pushing around algebraic symbols. Which is perfect for me, because that’s what I like to do to procrastinate! So I decided that it would probably be a good idea to work this out and leave it available somewhere (like on this blog), to make sure people in the future don’t have to work through tedious algebra. So…here it is! And to put the cherry on top, it did help me realize something that I’d never seen before.
WordPress makes it difficult (at least for me) to include large chunks of LaTeX, so I’ll take the more humble approach of uploading the proof as pictures.



And that’s it! Now you may be wondering, what is the insight that this little exercise left me with? It’s actually very subtle, but also very interesting:
Generally speaking, we teach our Intro Stats students that a correlation of 0 does not imply independence, right? Easy example: Take 
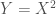
So now the list grows. Joint distributions for which a Pearson correlation of 0 implies independence:
(*) The multivariate normal
(*) The bivariate Bernoulli (but only the bivariate case).


You must be logged in to post a comment.