I think multilevel models are still “a thing”, right? Like they used to be all hot and sexy a few years ago but maybe they’ve started to become a little more common. The HLM software has made them very popular, although eventually I will rant about how much I dislike the whole “Level 1” and “Level 2” parlance that Raudenbush & Bryk helped disseminate. But for better or worse it’s here to stay and I need it if I want to communicate with my colleagues.
In any case, the model from which we will be simulating data in this post looks like this:

Where:

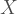

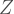


I know people reading this are probably more familiar withe the Level 1 and Level 2 approach of looking at things and I’m pretty sure it’s easy to make explicit its relationship with the way I stated the model, which is the Laird-Ware (1982) specification (this is, I think, a lot more common than the Raudenbush & Bryk one). Since I will be relying on matrices and matrix operations to simulate data, I thought it was a better idea to keep everything Laird-Ware.
In any case, by assuming that the random effects 

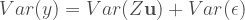



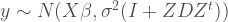
Because we’ve worked through the math a little bit here, now we know what we need to do in order to simulate data the way we want it: specify 


::UPDATE::
Following the advice of quite a few people, I would like to direct you to the improved version of this function that is now in MY PUBLISHED ARTICLE. This way you get a nice function that has been vetted by peer-review AND you can cite something if you choose to use it.
The code is all the way at the end of the article. Enjoy!
