This is an interesting insight that I had a couple of weeks ago when I was preparing to teach my class in Monte Carlo simulations. When working on ‘robustness-type’ simulations, we are usually not only interested in the unbiasedness and consistency but also the efficiency of our estimators. And a simple way to assess this efficiency is by looking at the estimated standard errors (SEs) of our parameter estimates. If they shrink or increase under violations of assumptions then we know something is going to be wrong with our p-values and Type I error rates and yadda-yadda. For the remaining of this article every time I talk about “standard errors” I’m most likely referring to the standard errors of regression coefficients within OLS multiple regression.
So…the only way I knew at first about how to assess SEs was in three steps:
(1) Run your simulation and save both regression coefficients and their standard errors.
(2) Calculate the mean of the SEs and the standard deviation of the coefficients.
(3) Compare the mean SE to the SD of the coefficients. Both should be close(ish).
The overall logic makes sense. In layperson’s terms, the standard deviation of the sampling distribution of the coefficients is the standard error. So it stands to reason that the average SE should be close to this quantity, even if it was derived empirically through simulation and not analytically. Behold an example:
set.seed(1)
b1 <- 0.5
reps<-5000
bb1 <- double(reps)
se1 <- double(reps)
var.e <- 1
var.x <- 1
N <- 100
for(i in 1:reps) {
x <- rnorm(n=N, mean=0, sd=var.x)
e <- rnorm(n=N, mean=0, sd=var.e)
y <- b1*x + e
mod<-summary(lm(y ~ x))
bb1[i]<-coef(mod)[2,1]
se1[i]<-coef(mod)[2,2]
}
> sd(bb1)
[1] 0.101642
>mean(se1)
[1] 0.1008769
Sure, that works. But this approach has always made me feel kinda awkward because it’s like you’re “double-dipping” in your simulation. Like… you need to simulate what the population may look like and then you need to simulate what the sampling behaviour may be… too much simulating, LoL. So the question comes to mind: We are well-acquainted with how to simulate data where the parameters are known in the population…but what about their variabilities? Does it even make sense to talk about “population standard errors”?
Well, the fact of the matter is that the way standard errors are defined in OLS multiple linear regression do involve population-level quantities. Therefore, I reasoned, it makes sense to set these in simulation studies whenever possible so we have a version of what the ‘true’ value would be. Let’s start from the beginning, simple linear regression. Of the various ways to calculate the SE for the regression coefficient in simple linear regression, I prefer this one for our purposes:

There are two elements here that we need to have control over: 

e <- rnorm(n=30, mean=0, sd=1)takes care of it so whatever goes in the SD argument states what the population error variance is. So we’re only left with figuring out how to get 

So I control the variance of
set.seed(1)
b1 <- 0.5
reps<-5000
bb1 <- double(reps)
se1 <- double(reps)
var.e <- 1
var.x <- 1
N <- 100
for(i in 1:reps) {
x <- rnorm(n=N, mean=0, sd=var.x)
e <- rnorm(n=N, mean=0, sd=var.e)
y <- b1*x + e
mod<-summary(lm(y ~ x))
bb1[i]<-coef(mod)[2,1]
se1[i]<-coef(mod)[2,2]
}
ssq <- (N-1)*var.x
>sqrt(var.e/ssq) ##population SE
[1] 0.1005038
mean(se1)
[1] 0.1008769
So both quantities match as well. But what about multiple OLS regression? Well, I think the multiple regression case is even simpler. We just need to remember that the SEs come from the diagonal of:

Again, I have control over 
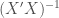
set.seed(1)
library(MASS)
reps <- 5000
N <- 100
b1 <- 1
b2 <- 1
R <- matrix(c(1, .5,
.5, 1),2,2)
se1<- double(reps)
se2<- double(reps)
for(i in 1:reps) {
dat <- mvrnorm(n=N, mu=c(0,0), Sigma=R)
x1<- dat[,1]
x2<- dat[,2]
e <- rnorm(n=N, mean=0, sd=1)
y <- 1 + b1*x1 + b2*x2 + e
mod <- lm(y ~ x1 + x2)
se1[i] <- coef(summary(mod))[2,2]
se2[i] <- coef(summary(mod))[3,2]
}
pop.se1 <- sqrt(diag(1*(solve(R)))/N)[1] ##these are my population SEs
pop.se2 <- sqrt(diag(1*(solve(R)))/N)[2] ##these are my population SEs
> pop.se1
[1] 0.1154701
> mean(se1)
[1] 0.1174567
> pop.se2
[1] 0.1154701
> mean(se2)
[1] 0.117328
So… yeah. POPULATION SEs FTW!!!!
