So while I was helping out a student in designing a simulation study I noticed something slightly odd. Most of the time, if you’re running a simulation of the type “the robustness of …. (insert your favourite statistical method here)” you’ll probably want to say something about how it performs under non-normality. And an easy way to characterize non-normality is through the 3rd moment (skewness) and 4th moment (kurtosis). That’s all fine and dandy. What I realized quickly is that some people may not be aware that those two moments are not independent and you can’t just willy-nillingy choose their values as you please for simulation conditions. What I’m going to be showing here is not new. It’s been around for almost a century now, but perhaps it is shown in such an impenetrable way that either most people can’t follow it or they just forgot about it. Maybe this could help clarify things a little bit.
Define skewness as:
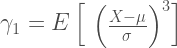
and kurtosis as:

Where 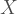
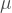
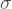

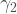
Now, assume that ![E[X]=0](https://s0.wp.com/latex.php?latex=E%5BX%5D%3D0+&bg=ffffff&fg=444444&s=1&c=20201002)
![\sigma_{X}=E[X^{2}]=1](https://s0.wp.com/latex.php?latex=%5Csigma_%7BX%7D%3DE%5BX%5E%7B2%7D%5D%3D1+&bg=ffffff&fg=444444&s=1&c=20201002)
![E[X^{3}]=\gamma_{1}](https://s0.wp.com/latex.php?latex=E%5BX%5E%7B3%7D%5D%3D%5Cgamma_%7B1%7D+&bg=ffffff&fg=444444&s=1&c=20201002)
![E[X^{4}]=\gamma_{2}](https://s0.wp.com/latex.php?latex=E%5BX%5E%7B4%7D%5D%3D%5Cgamma_%7B2%7D+&bg=ffffff&fg=444444&s=1&c=20201002)

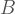
![E[AB]^{2} \leq E[A^{2}]E[B^{2}]](https://s0.wp.com/latex.php?latex=E%5BAB%5D%5E%7B2%7D+%5Cleq+E%5BA%5E%7B2%7D%5DE%5BB%5E%7B2%7D%5D&bg=ffffff&fg=444444&s=2&c=20201002)
Substitute 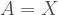
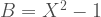
![(E[X(X^{2}-1)])^{2} \leq E[X^{2}]E[(X^{2}-1)^{2}]](https://s0.wp.com/latex.php?latex=%28E%5BX%28X%5E%7B2%7D-1%29%5D%29%5E%7B2%7D+%5Cleq+E%5BX%5E%7B2%7D%5DE%5B%28X%5E%7B2%7D-1%29%5E%7B2%7D%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
![(E[X^{3}-X])^{2} \leq E[X^{2}]E[X^{4}-2X^{2}+1]](https://s0.wp.com/latex.php?latex=%28E%5BX%5E%7B3%7D-X%5D%29%5E%7B2%7D+%5Cleq+E%5BX%5E%7B2%7D%5DE%5BX%5E%7B4%7D-2X%5E%7B2%7D%2B1%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
![(E[X^{3}]-0)^{2} \leq (1)E[X^{4}-2E[X^{2}]+1]](https://s0.wp.com/latex.php?latex=%28E%5BX%5E%7B3%7D%5D-0%29%5E%7B2%7D+%5Cleq+%281%29E%5BX%5E%7B4%7D-2E%5BX%5E%7B2%7D%5D%2B1%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
![(E[X^{3}])^{2} \leq E[X^{4}]-2+1](https://s0.wp.com/latex.php?latex=%28E%5BX%5E%7B3%7D%5D%29%5E%7B2%7D+%5Cleq+E%5BX%5E%7B4%7D%5D-2%2B1+&bg=ffffff&fg=444444&s=2&c=20201002)
![(E[X^{3}])^{2} \leq E[X^{4}]-1](https://s0.wp.com/latex.php?latex=%28E%5BX%5E%7B3%7D%5D%29%5E%7B2%7D+%5Cleq+E%5BX%5E%7B4%7D%5D-1+&bg=ffffff&fg=444444&s=2&c=20201002)
![(E[X^{3}])^{2}+1 \leq E[X^{4}]](https://s0.wp.com/latex.php?latex=%28E%5BX%5E%7B3%7D%5D%29%5E%7B2%7D%2B1+%5Cleq+E%5BX%5E%7B4%7D%5D+&bg=ffffff&fg=444444&s=2&c=20201002)
Which looks exactly was the inequality found on the wiki article for kurtosis.
If we wanted to express it in terms of excess kurtosis, as it is sometimes presented to make the kurtosis of the normal distribution 0, then we just need to substract 3 from both sides of the inequality to make it:

As I said previously, this is not a new result but I am starting to realize many people are not aware of it. And if simulation studies are conducted where levels of skewness and (excess) kurtosis are chosen outside of this parabola, the results do not make sense. So if you either use Monte Carlo simulation studies to inform your data analysis practice or do Monte Carlo simulation studies, it would be a good idea to keep this quadratic relationship in mind to make sure the stuff you’re reading is fully legit 😉
