While I am preparing for a more “in-depth” treatment of this Twitter thread that sparked some interest (thank my lucky stars!) , I ran into a couple of curious distributions that I think highlight an important lesson: not EVERYTHING needs a copula 😉 Sure, they’re flexible and powerful modelling approaches. But at the end of the day there are other methods to create multivariate, non-normal distributions. And many of them have very elegant theoretical properties that allow us to expand our the intuitions about these distributions from the univariate to the multivariate setting.
So here I present two distributions which can be generalized from their univariate to a multivariate definition without invoking a copula.
Multivariate Poisson Distribution
The Poisson distribution is closed under convolutions. For purposes of this post, that means that if 
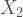
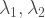


So let’s start easy, the bivariate case. To construct a bivariate Poisson random vector 
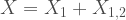
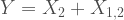
Where 
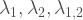
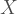
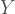


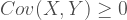
Using the above property we can derive the joint probability function of 

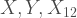


where 

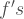

From this process I could expand it to, say, a trivariate Poisson random variable by expressing the 3-D vector 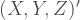
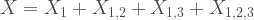

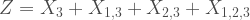
Where all the X’s are themselves independent, Poisson distributed and the terms with double (and triple) subscript would control the level of covariance among the Poisson marginal distributions. If you repeat this iteratively adding more and more terms to the summation then you can increase the dimensions of the multivariate Poisson distribution.
Multivariate Exponential Distribution
The univariate exponential distribution is also (sort of) closed under convolution. But, in this very specific case, it’s closed under weighted minima convolution. For this post, that means that if 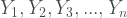


We can start very similarly as with the previous case by defining how the bivariate distribution would look like. Here we start with:

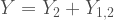
where 




And the joint cumulative density function of the bivariate vector

Moral of the story
If you know me, you’ll know that I tend to be overly critical of the things I like the most, which is a habit that doesn’t always makes me a lot of friends, heh. Because I like copula modelling and I like the idea of non-normal, multivariate structures, I also like to see and understand the cases where defining multivariate structures that do not need a copula may give us insights. For the particular two cases above, I am exploiting the fact that sums of these types of random variables also result in the same type of random variable (i.e., closed under convolution) which, for better or worse, is a very useful property that not many univariate probability distributions have. Nevertheless, when they *do* have it, it is perhaps wise to use them because, at the end of the day, using copulas to either simulate or model multivariate data does not imply the copula distribution *becomes* the “multivariate” version of that distribution. A Gaussian copula with gamma-distributed marginals is not a “multivariate gamma distribution”. It is… well… a Gaussian copula with gamma distributed marginals. If you change the copula function for something else (say an Archimidean copula) the multivariate properties change as well. Which brings us to a very sobering realization: with the exception of some very select types of multivariate distributions (usually those closed under convolution) we don’t always have well-defined extensions of multivariate distributions. For example, there are more than 10 different ways to define distributions that would satisfy what one would call a “multivariate t distribution”. Whichever characterization one chooses is usually contingent on the intended use for it. I guess this helps highlight one of the oldest pieces of advice I ever received: You know you have become a good methodologist when you realize the only correct answer to every data analysis question is simply “it depends”.
